Mastering Spark on Google Cloud in Under 10 Minutes
Written on
Introduction to Apache Spark
Apache Spark is a powerful distributed data processing framework that allows for the handling of high-speed data streams. It includes libraries for SQL, machine learning, data science, and graph processing. Spark's capability to process petabytes of data simultaneously makes it up to 100 times quicker than Hadoop’s MapReduce.
While Spark is often deployed over Hadoop clusters, setting up an on-premises Hadoop cluster can be labor-intensive and time-consuming. During my Master's studies, I encountered the need for greater computing power. I attempted to establish my own Hadoop cluster using some old PCs from our lab, but the process was incredibly burdensome, especially without a solid background in infrastructure systems.
This tutorial aims to assist those who wish to run their Spark jobs quickly and affordably on a distributed cluster. I hope to document the steps that would have significantly eased my journey back then!
Getting Started with Spark on GCP
In this article, we will explore how to utilize Cloud Computing to launch our first Spark job in under 10 minutes! We will be leveraging Google Cloud Platform’s (GCP) Cloud Dataproc to enhance both speed and efficiency.
Step-by-Step Guide to Deploying a Spark Cluster
- Begin by navigating to GCP and searching for Dataproc.
- Create an Apache Hadoop cluster.
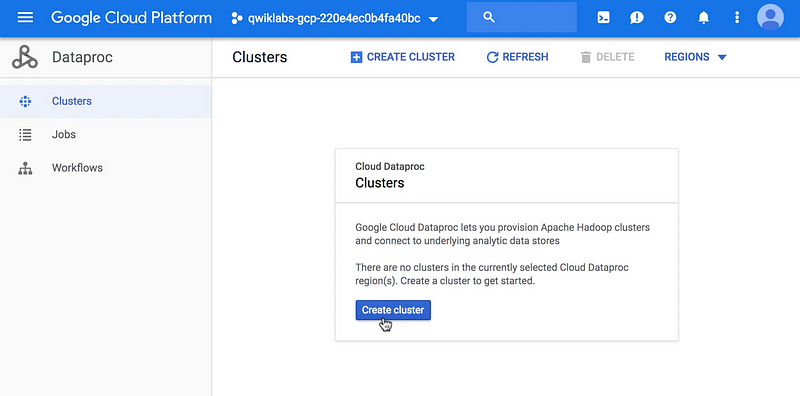
- Assign a name and select the cluster properties. For initial trials, you can stick with the default settings.
- In the Jobs section, click on "Submit a Job."
- Complete the job details. Set the job type to Spark and link it to your Spark class (and your .jar file). For practice, you can run this Spark job that calculates the value of pi.
- Ensure that the Spark Job is visible in the Jobs section.
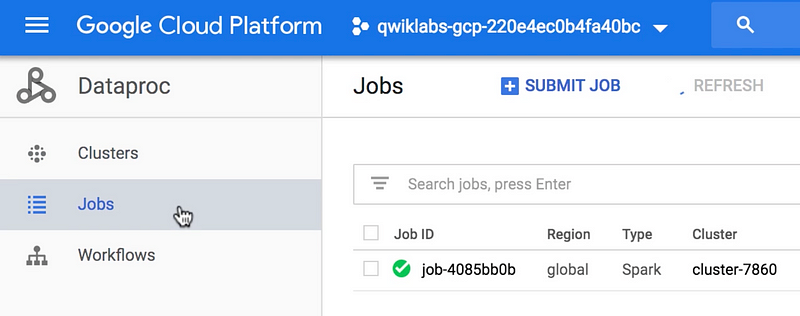
- Wait for the job to complete. You can click on the cluster to check its resource usage and monitor ongoing jobs.
- After the job finishes executing, consider shutting down the cluster to save resources, unless persistent data is necessary.
In total, it took me less than 4 minutes to set up the cluster and run the Spark job, which completed in just 37 seconds using the default cluster settings.
Did you find this guide helpful? If so, consider subscribing to my email list to receive notifications about my latest content.
Stay Connected
Get updates whenever David Farrugia publishes new articles. By signing up, you will create a Medium account if you don't already have one.
Also, think about supporting me and other writers on Medium through my referral link below, which grants you unlimited access to all articles for just $5 a month.
Want to buy me a coffee?
Support David Farrugia via PayPal.Me
I welcome your thoughts on this topic or anything related to AI. Feel free to reach out via email at [email protected] if you'd like to connect.
LinkedIn — Twitter