Mastering Regex: Your Comprehensive Guide to Pattern Matching
Written on
Chapter 1: Understanding Regular Expressions
Regular expressions, commonly referred to as regex, consist of a series of characters that create a search pattern. These expressions are invaluable for searching and replacing text within strings, allowing for complex operations that would be tedious if done manually. Regex serves as a versatile tool applicable in various contexts, from file systems to databases, making it essential for programmers of all experience levels.
Whether you're an experienced developer or just starting out, the potential of regex is often underappreciated. It enables precise searching and manipulation of text data, making it useful for tasks such as debugging, validating, or processing strings. For example, regex can be employed to extract phone numbers from a document and replace them with placeholders or to eliminate special characters from HTML content.
Moreover, regex is integrated into nearly every programming language. Whether you're in IT, SEO, or data analysis, regex can significantly streamline your workflow. Although regex can seem daunting at first, its application in daily tasks can be transformative. This blog aims to guide you in mastering regex.
Chapter 2: How Regex Functions
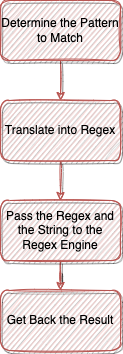
Using regex is relatively straightforward, as most programming languages support regex matching natively or through libraries. The initial step involves identifying the pattern you wish to locate within a string, which can be any character sequence. Once you have your pattern, you'll need to convert it into a regex format. It's advisable to test your regex with a validation tool available online before applying it in your code.
Once your regex is established, find the appropriate regex engine for your programming language. Familiarizing yourself with its documentation can be quite beneficial. You will then pass the regex pattern along with the target string to the regex engine, which will analyze the string and return results based on the engine's specifications.
Section 2.1: Building Your First Regex
Before diving into regex creation, let’s review the fundamental syntax elements:
- / — Delimiter (indicates the start and end of regex)
- ? — Matches 0 or 1 time
- * — Matches 0 or more times
- + — Matches 1 or more times
- [] — Specifies a range of acceptable values
- {} — Denotes an exact number of characters
- | — Creates alternative options
- () — Groups patterns
- i — Enables case-insensitive matching
- ^ — Anchors to the start of the string
- $ — Anchors to the end of the string
To illustrate, let’s construct a regex to validate hexadecimal color codes.
Step 1: Identify the Pattern
Hexadecimal colors typically begin with a # followed by six characters, which can be digits (0-9) or letters (A-F).
Step 2: Convert to Regex
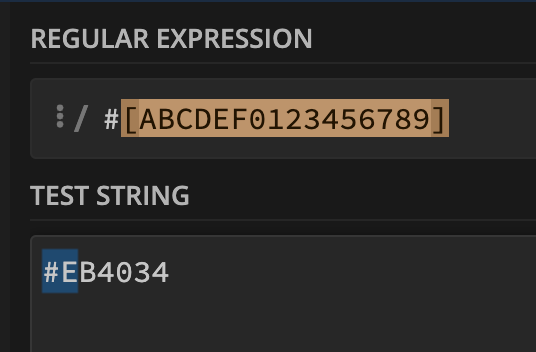
Utilizing a regex testing site, we start with the possible characters: /#[ABCDEF0123456789].
The regex will only match the first two characters, as it is currently designed. To rectify this, we can append the + operator to allow for one or more repetitions of characters within the brackets. Additionally, instead of listing every character, we can specify ranges (e.g., A-F and 0-9) and make the # optional with the ? operator.
Testing the Adjustments
After these modifications, the regex should now correctly match valid hex codes, including those with three characters, such as #B63.
Section 2.2: Refining the Regex
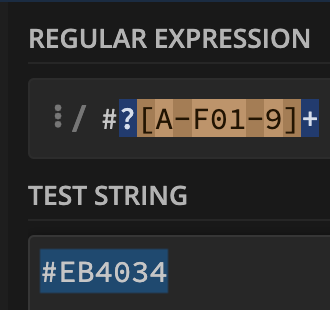
For cases with incorrect formatting, we can use {6} to enforce that hex codes contain exactly six characters. However, since valid hex codes can also have three characters, we should modify the regex to accommodate both formats using the | operator.
Our refined regex now looks like this: /#?([A-F0-9]{6}|[A-F0-9]{3})/.
To ensure case insensitivity, we can either list both uppercase and lowercase letters or apply a case-insensitive modifier.
Section 2.3: Finalizing the Regex
To guarantee that the regex matches the entire string, we must employ anchors (^ for the start and $ for the end). This ensures that our regex only validates complete hex codes without partial matches.
To incorporate whitespace handling, we can utilize s*, which instructs the regex engine to ignore any surrounding whitespace. The final regex will be: /^s*#?([A-F0-9]{6}|[A-F0-9]{3})s*$/i.
With this, we have successfully built our first regex for validating hexadecimal values. Remember, the principles learned here can be applied to build more complex regex expressions as you continue to practice.
If you found this guide helpful, consider subscribing for updates whenever new content is released.