Understanding the Role of Intercept in Machine Learning Models
Written on
Chapter 1: Introduction to Regression Modelling
In the realm of Data Science and Machine Learning, one of the most illuminating experiences was my initial lesson on regression modelling and the linear relationships between variables. Prior to this, my exposure had mostly involved GitHub and Python, but that day marked a pivotal moment where many of us grasped how theoretical concepts translate into real-world applications. For me, having not engaged with math and statistics for nearly a decade made some of the material quite challenging to digest. Yet, I was pleasantly surprised to discover that my sister, in her first year of Economics, was equally astounded at how those abstract theories had practical implications.
The education we receive in college often lacks the hands-on application necessary for a thorough understanding of fundamental concepts, which can leave us perplexed as we delve into Data Science years later. If you resonate with this experience, today we’ll take a closer look at a foundational yet sometimes overlooked concept—the intercept in regression analysis—especially when utilizing libraries like Sklearn.
A valuable tip for anyone seriously considering a career in data science is to refresh your mathematical knowledge. This investment will undoubtedly pay off. While the landscape of technology and programming languages is ever-changing, the core mathematical principles will persist. I’m currently on a self-directed journey to enhance my math skills, and I plan to share my experiences in future articles, so stay tuned!
Chapter 2: Revisiting the Basics
Let’s revisit the core principles of regression modelling in machine learning. In linear regression, our goal is to predict a continuous outcome variable, Y, based on a predictor variable, X, under the assumption of a linear correlation between the two. This relationship can be expressed as:
y = B0 + B1*x
Here, B1 represents the slope of the line, while B0, the intercept, indicates the value of the dependent variable when the independent variable equals zero.
For instance, consider a scenario where I prepare a dish that requires 10 minutes for preparation and an additional 5 minutes of chopping ingredients per guest, plus 10 minutes for cooking. In this case, the slope (B1) would be 5, and the intercept (B0) would be 20, accounting for the initial setup and cooking time.
Thus, the equation can be framed as:
Y = 5X + 20
If I’m hosting four guests, the total cooking time would be:
Y = 5*4 + 20 = 40 minutes.
The function could be expanded to include more variables, such as additional shopping or cooking time for each guest:
Y = B1*x + B2*x + B3*x + ... + Bn*x + B0.
So, how does Sklearn determine the optimal equation? It's primarily through an optimization/minimization approach. The method of least squares aims to minimize the sum of the squared residuals for each equation result.
In this context:
- Yi is the actual value,
- yi is the predicted value,
- N is the total number of elements in the dataset.
The choice of squared values over absolute values serves to amplify penalties for larger discrepancies between predicted and actual values.
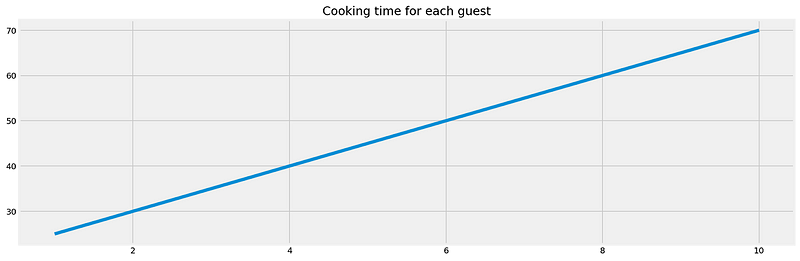
For example, if we assume we know the total cooking time for a range of guests without knowing B1:
number of guests = x = [1, 3, 5, 10, 15, 20]
total cooking minutes = y = [25, 35, 45, 70, 95, 120]
When testing different values for B0, we could achieve varying Mean Squared Errors (MSE), helping us to pinpoint the most suitable coefficient. Sklearn utilizes a technique called Gradient Descent for this purpose, which is worth exploring further.
Before we delve deeper into the intercept, let’s note that aside from MSE, there are other evaluation metrics like mean absolute error and mean log error, each serving different purposes in assessing model accuracy.
Chapter 3: The Intercept's Significance
As previously mentioned, the intercept represents the target variable's value when all features are zero, indicating where the function crosses the y-axis. In Sklearn, we can choose to include or exclude the intercept in our linear model via a hyperparameter. Interestingly, omitting the intercept can sometimes enhance model performance, effectively forcing the line through the origin. This means we assert that when all coefficients are zero, the target variable will also be zero.
Does this assertion hold true? It largely depends on the specific context of your model. For example, if predicting the number of rooms in a property based on various features (like bathrooms and bedrooms), a property devoid of these features might indeed have zero rooms. Conversely, if we were to predict property prices under the same conditions, it’s unlikely that the value would be zero.
In cases where certain predictors cannot realistically equal zero, dropping the intercept may be a viable option, as it may not provide meaningful insights into the relationship between X and Y.
When we constrain the intercept to zero, it can amplify the coefficients' values, which can be misleadingly interpreted as greater significance. In reality, this increase is simply due to a steeper slope rather than genuinely stronger coefficients.

However, determining whether to include the intercept can be complex. In situations with numerical predictors that are uncentered, the decision may appear straightforward. Yet, when dealing with categorical variables that have been transformed into dummy variables or predictors centered around their mean, the intercept can take on greater importance.
For instance, dummy variables, which only indicate the presence or absence of a feature (1 or 0), gain significance when both values equal zero, indicating a lack of the represented features. In mixed models with both categorical and centered numerical variables, the intercept remains crucial and should generally not be dropped.
Ultimately, it's essential to remain realistic about the business case rather than simply manipulating the intercept to achieve more favorable coefficients or R² values. Such practices can lead to overfitting, as we may be introducing unnecessary complexity to the model.
In conclusion, understanding the role of the intercept is vital in developing effective machine learning models. I encourage you to stay tuned for future articles covering techniques for managing categorical features and other related topics.
The first video titled "Adding and Interpreting Intercept in Model" provides insights into the importance of the intercept in machine learning algorithms.
The second video, "Display the Intercept and Coefficients for a Linear Model," explores how to visualize and understand these components in regression analysis.
Thank you for reading! For more insights, feel free to check out my previous articles on related topics.